
How to Build an AI Citation Strategy
Build an ai citation strategy that boosts AI visibility, trust, and accuracy with better sourcing, schema, authorship, and QA.




AI systems are becoming a source of traffic, trust, and product evaluation long before a buyer reaches your site. That changes how visibility works. Ranking still matters, but being selected as a source now matters just as much.
An effective AI citation strategy gives your organization a way to influence that selection. It helps your content get surfaced, parsed, trusted, and cited by systems like ChatGPT, Perplexity, Gemini, and AI Overviews. It also gives internal teams a framework for how AI-assisted outputs should reference evidence, disclose sources, and reduce citation errors.
The strongest programs treat citations as an operating system, not a formatting task. That means source quality, retrieval, entity clarity, structured data, editorial controls, and measurement all need to work together.
What an AI citation strategy includes
At a basic level, an AI citation strategy answers two questions: how your organization should use citations when AI produces content, and how your organization should earn citations from AI systems that summarize the web.
Both matter. One protects accuracy and trust inside your workflows. The other increases visibility outside them.
A practical strategy usually covers:
- Source hierarchy
- citation rules
- schema and metadata
- publishing standards
- authorship signals
- monitoring and QA
That broader view is what separates AI citation work from ordinary content production. If a page is hard to parse, weakly attributed, thinly sourced, or missing machine-readable context, it may never become citation-eligible even if the writing is good.
Why AI citation strategy is different from traditional SEO
Traditional SEO rewards relevance, links, and technical accessibility. AI citation systems also care about those signals, but they add another layer: extractability.
A model or answer engine needs to identify who said something, what exactly was said, when it was published, whether the claim is supported, and whether the page appears trustworthy enough to quote. That pushes content teams toward clearer structure and stronger provenance.
This shift explains why many brands with decent rankings still fail to earn AI citations. Their pages often have one or more of these problems:
- Claims: important facts are buried in long paragraphs
- Authorship: the page does not make the author or organization explicit
- Evidence: assertions are not tied to sources or primary data
- Formatting: the answer is difficult to extract into a clean snippet
- Freshness: the material looks dated or lacks update signals
In other words, visibility is no longer just about being found. It is about being usable as evidence.
The core components of an AI citation strategy
A good strategy has a few parts that reinforce one another. If one is missing, performance usually stalls.
Source governance for AI citations
AI systems are far more likely to trust pages that show disciplined sourcing. Internal teams need the same discipline when using AI to draft, summarize, or answer questions.
That starts with a source hierarchy. Official documentation, standards bodies, government publications, original data, product docs, and peer-reviewed material should usually sit above general summaries. If your content cites weak sources, AI systems have less reason to trust it as a source itself.
This is also where disclosure rules matter. In regulated or high-stakes environments, teams need clear rules for when AI was used, what it was used for, and who reviewed the output.
Entity signals and machine-readable trust
Many teams still think page-level optimization is enough. It is not.
AI systems look for stable entity signals that explain who the publisher is, who wrote the content, what the page is about, and how it relates to a broader topic cluster. That is where structured data, author pages, organization pages, canonical URLs, and consistent naming become useful.
When those signals are missing, models may still crawl the page, but they have less confidence in how to interpret it.
Content design for extractable answers
The pages that earn citations often share a simple trait: they make key facts easy to lift without distorting the meaning.
That does not mean writing robotic content. It means building pages with strong information architecture. Clear definitions, concise answer blocks, question-led headings, visible dates, and explicit statistics make citation more likely because they reduce ambiguity.
A citation-friendly page tends to place the claim and the support close together. It does not force the model to infer too much.
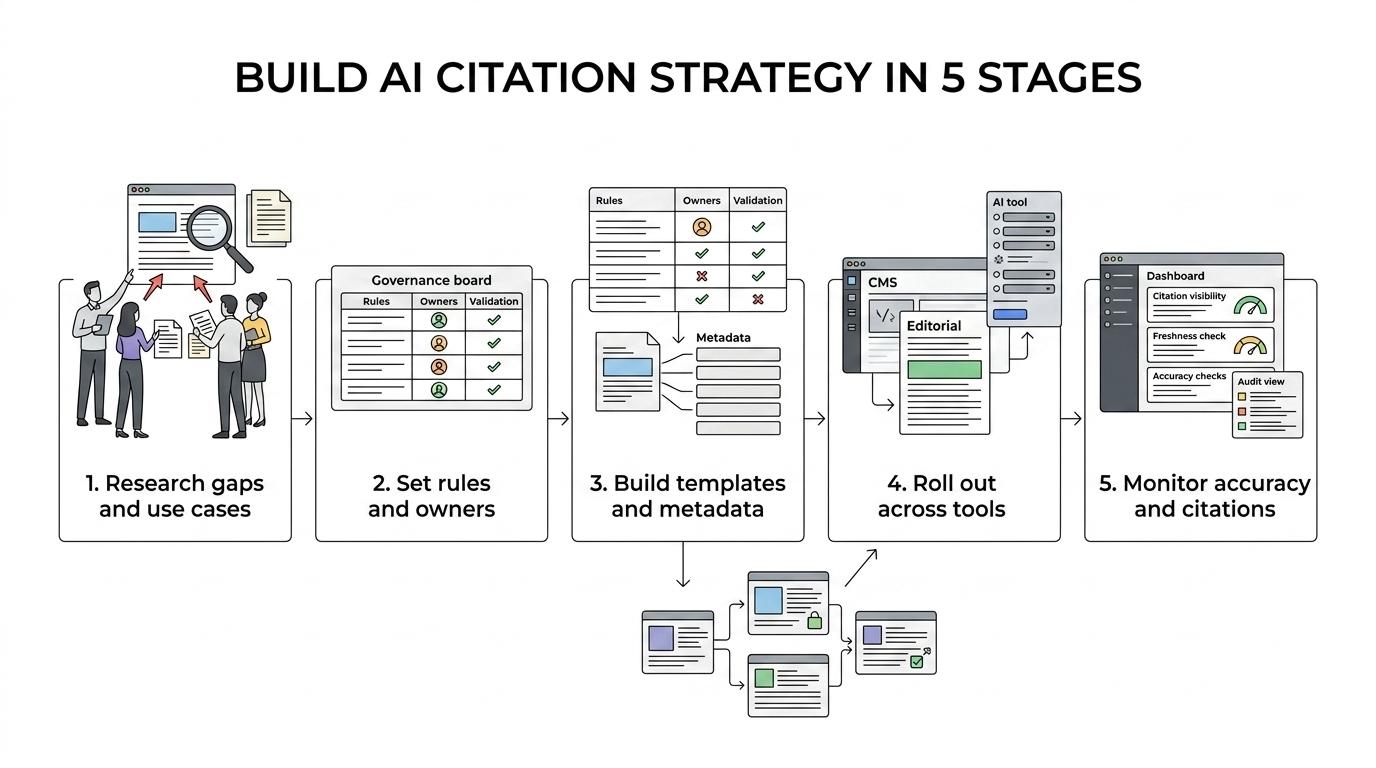
A practical framework for building AI citation strategy
Most organizations do better when they build this in stages instead of trying to fix everything at once. The table below shows a clean way to structure the work.
[markdown] | Stage | Primary goal | Key output | | --- | --- | --- | | Research | Identify use cases, risks, and current gaps | Source taxonomy and gap analysis | | Planning | Set rules, owners, and validation standards | Governance framework | | Design | Build retrieval, metadata, and content requirements | Workflow and templates | | Implementation | Roll out across CMS, editorial, and AI tools | Production process | | Monitoring | Track accuracy, freshness, and citation visibility | Dashboards and audits | [/markdown]That sequence keeps teams from over-investing in tools before the operating model is clear.
After the research phase, most teams should make a few non-negotiable decisions early:
- Which source types are acceptable by use case
- Which claims require citations or evidence
- Which pages are expected to earn AI citations
- Which stakeholders own QA, schema, and content freshness
Without those decisions, AI citation work turns into scattered optimization with no durable standard behind it.
Content architecture that improves AI citation eligibility
If your goal is inbound citation growth, site architecture matters as much as individual page quality.
Many high-performing pages follow a repeatable pattern. They answer one clear question, define terms early, support claims with named evidence, and make authorship obvious. They are not trying to be mysterious or overly clever. They are trying to be useful and quotable.
A strong page template often includes:
- a direct opening answer
- descriptive subheadings
- visible publish and update dates
- named author or reviewer
- outbound references where appropriate
- structured data that matches the page type
This is one area where entity-first thinking helps. A site should not just publish isolated articles. It should build a clear knowledge system around the company, its experts, its products, and the subjects it wants to own.
Schema and metadata for AI citations
Structured data does not guarantee citations, but it improves machine readability and reduces confusion. That is valuable when models need to decide what a page is, who stands behind it, and how fresh it is.
The most useful schema types depend on the site, though these usually appear in strong implementations:
- Organization: to identify the publisher clearly
- Person: to connect authors and subject matter experts
- Article: to define editorial content
- FAQPage: for tightly structured Q&A content
- Product or SoftwareApplication: for software and feature pages
Metadata discipline matters just as much. Canonical URLs, consistent bylines, last-updated dates, and stable page titles often look boring from the inside, but they make source interpretation easier from the outside.
Outbound AI citation strategy for internal teams
Many organizations focus only on earning citations, then overlook the risk of AI-generated outputs containing weak or fabricated references.
That is a mistake, especially in B2B, finance, healthcare, legal, or enterprise settings. An outbound citation strategy should define how AI can retrieve sources, how citations are attached, and where human review is required.
The safest pattern is retrieval-backed generation. The system retrieves approved sources first, then drafts from those sources, then renders citations from verified metadata. It should not invent references from model memory.
A useful internal policy usually includes:
- Approved repositories: official docs, internal knowledge bases, trusted external sources
- Validation checks: live URLs, matching titles, resolved identifiers
- Human review: mandatory for high-risk claims and sensitive topics
- Disclosure language: clear statements about AI assistance and editor review
This is where standards from groups like NIST, ICMJE, WAME, and Crossref become helpful. They point teams toward lifecycle controls, transparency, persistent identifiers, and human accountability.
Metrics that show whether AI citation strategy is working
AI citation work needs measurement or it turns into guesswork dressed up as strategy.
Start with a small scorecard that covers both quality and visibility. Quality tells you whether your sources and workflows are reliable. Visibility tells you whether AI systems are actually citing your material more often.
The best starting metrics are usually:
- Citation validity rate
- claim-support rate
- primary-source ratio
- freshness score
- AI citation share across priority topics
- human correction rate
If you only track citations earned, you can miss serious quality issues. If you only track QA, you can miss whether the market is actually seeing your content through AI interfaces.
Auditing AI citation performance
Regular audits create momentum because they turn vague assumptions into concrete fixes.
A strong audit asks simple but revealing questions. Can AI systems access the page? Is the author visible? Is the answer self-contained? Are dates explicit? Are the claims sourced? Does the schema reflect the actual content? Has the page been refreshed recently?
Those audits often expose the same pattern: content teams have plenty of information, but not enough structure.
Common mistakes that weaken AI citation results
Most failures come from process problems, not from a lack of publishing effort.
Teams often produce more content when they should improve the citation readiness of the content they already have. Others over-focus on keywords while ignoring authorship, entity clarity, and evidence design. Some publish polished pages that are impressive to humans but hard for AI systems to quote accurately.
The most common mistakes include:
- treating citations as a late-stage formatting task
- publishing pages with no visible authorship or update history
- relying on weak secondary sources for important claims
- hiding key definitions inside long narrative sections
- using schema inconsistently across templates
- failing to review aging content in fast-changing categories
Fixing these issues rarely requires a total rebuild. It usually requires standards, templates, and ownership.
What to put in place over the next 90 days
A strong AI citation strategy does not need to begin as a massive transformation. It needs a controlled rollout with clear priorities.
In the first month, define the source hierarchy, identify the pages most likely to earn AI citations, and set minimum metadata requirements. In the second month, update templates, strengthen schema, and create a review process for high-value pages. In the third month, begin tracking citation visibility, freshness, and support quality across a focused topic set.
That kind of cadence works because it connects technical SEO, editorial practice, and AI search visibility into one operating model. It also builds something more durable than a traffic tactic: a system that helps your brand become a source AI products are willing to quote.


